
The cost to implement AI at your firm is almost certainly lower than you think. Here's the data.
I spend most of my time advising PE portfolio companies on AI strategy. The same conversation plays out in almost every boardroom: the CFO asks what it costs to "do AI," someone quotes a six-figure annual API bill from OpenAI or Anthropic, and the room goes quiet. The project stalls. Six months later, they're still running the same manual processes, losing ground to competitors who moved faster.
Here's the thing: that six-figure number is wrong. Not because AI is cheap, but because the assumption that you need to pay a frontier model provider to unlock value is, for most use cases, simply not supported by the data.
I'm not making a theoretical argument. The benchmarks, the economics, and the case studies all point to the same conclusion: the models that already exist — many of them free, open-source, and able to be run on hardware that fits on a desk — can handle the vast majority of what PE portfolio companies need AI to do. And the gap between those models and the ones you pay $15–25 per million tokens for is, on most dimensions, functionally zero.
Let me walk through the evidence.
The Gap Is Closing Faster Than You Think
Two years ago, the performance gap between open-source models and the best proprietary offerings was real and significant. On MMLU, the standard knowledge benchmark, the best closed model scored 86.4% while the best open alternative managed 70.5%. This was a 16-point chasm. If you wanted AI that actually worked, you paid for it.
That world no longer exists.
As of early 2026, open-source models lead or match frontier closed models on four of the six most commonly cited LLM benchmarks, and the remaining two gaps are narrowing fast. Five independent open-source model families (DeepSeek, Qwen, Kimi, Moonshot's GLM, and Mistral) have simultaneously reached frontier quality.
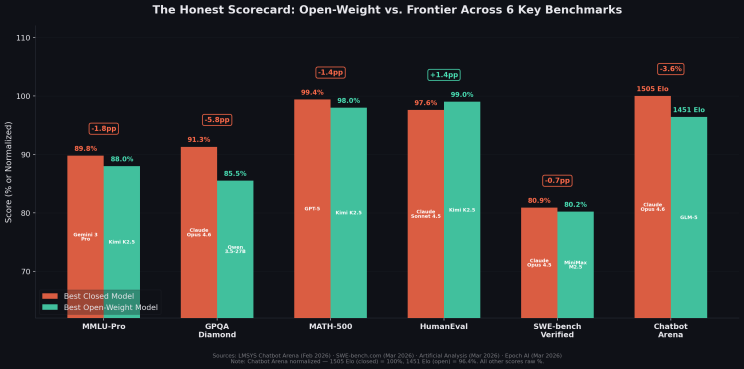
The numbers tell the story. On MMLU-Pro (the harder variant that hasn't saturated), the gap is 1.8 percentage points with Gemini 3 Pro at 89.8% and Kimi K2.5 at 88.0%. On MATH-500, Kimi K2.5 scores 98.0% versus GPT-5's 99.4%. On HumanEval, the standard code generation benchmark, Kimi K2.5 leads at 99.0% versus Claude Sonnet 4.5's 97.6%. On SWE-bench Verified, the most demanding real-world software engineering benchmark, MiniMax M2.5 trails Claude Opus 4.5 by just 0.7 percentage points: 80.2% versus 80.9%.
Where frontier models still lead meaningfully: GPQA Diamond, a graduate-level science benchmark, shows Claude Opus 4.6 at 91.3% versus Qwen 3.5's 85.5% (a 5.8-point gap). And Chatbot Arena, which measures human preference in open-ended conversation, shows Claude Opus 4.6 at 1505 Elo versus GLM-5's 1451. This is a 54-point gap representing roughly a 54% win rate for the frontier model.
These are real advantages. But they matter most for tasks where deep scientific reasoning or conversational nuance are the primary value drivers. These are a narrow slice of what most enterprises need.
"Good Enough" Is Better Than You'd Expect
The question every executive should be asking is not "which model scores highest on every benchmark?" but rather "what level of performance do I actually need for the tasks I'm trying to automate?"
This is the concept of task–model fit: matching model capability to task complexity rather than defaulting to the most expensive option.
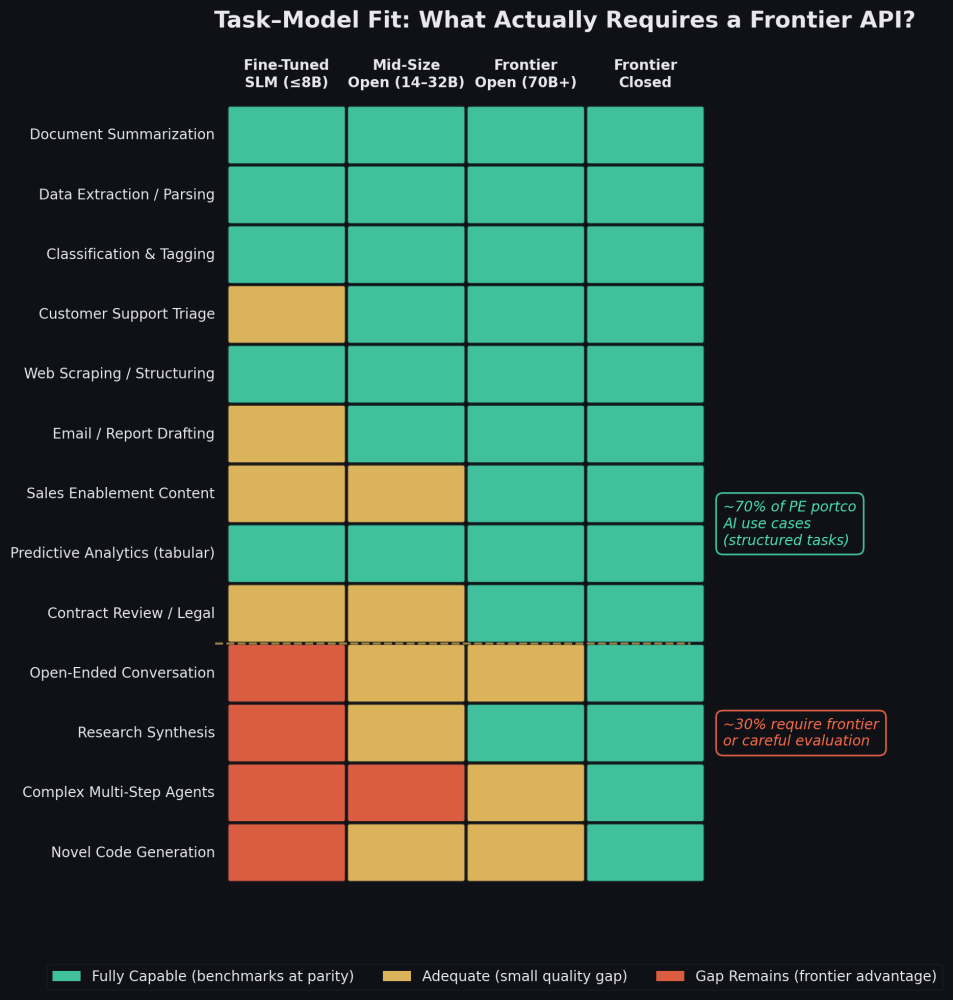
When you map common PE portfolio company use cases against model tiers, a clear pattern emerges. Document summarization, data extraction, classification, web scraping, and predictive analytics on tabular data — all of these are well-defined, structured tasks with clear inputs and measurable outputs. Open-source models perform at full parity on every relevant benchmark for these workloads. Even a mid-size 14–32B parameter model running on modest hardware handles them without breaking a sweat.
Customer support triage, email drafting, and sales enablement content sit in a middle tier — open-source models are adequate, but the Chatbot Arena gap means frontier models produce slightly better tone and nuance in open-ended generation. Whether that marginal quality difference justifies a 5–10x cost premium depends on the specific application.
The tasks where frontier models genuinely earn their keep (complex multi-step agentic workflows, novel code generation on unfamiliar codebases, and open-ended creative work) represent roughly 30% of typical PE portfolio company AI use cases. Important work, but not the majority.
For the web scraping example I raised at the top: a year-old open-source model is not just sufficient, it's often better than a frontier API call. Web scraping is a structured, code-heavy task. HumanEval scores are at ceiling across the board. You're paying a premium for capabilities you don't need.
The SLM Play: Fine-Tuned Models That Beat Frontier on Your Domain
The open-source advantage gets even more pronounced when you consider fine-tuning. A small language model (SLM) with 7–14 billion parameters, fine-tuned on your specific domain data, can outperform frontier models on the exact tasks your business cares about at a fraction of the cost and latency.
The data from Q1 2026 is unambiguous. On financial classification tasks, a fine-tuned Phi-3 model achieved 96% accuracy versus GPT-4o's 80% (a 16-point gap in favor of the smaller, cheaper model). In healthcare, a domain-specific SLM hit a 0.9% miss rate on protected health information extraction, versus GPT-4o's 14.6% miss rate (that's 99.1% versus 85.4% accuracy on a task where errors have regulatory consequences). Across 287 enterprise deployments analyzed by ZenML in March 2026, fine-tuned SLMs delivered 90% cost reductions and 3x faster response times versus frontier APIs, with equal or better accuracy on domain-specific tasks.
Note: these benchmarks use GPT-4o as the frontier baseline, still the most widely deployed enterprise API model. GPT-5 offers stronger general reasoning but at higher per-token pricing, which widens rather than narrows the cost advantage of fine-tuned SLMs on domain-specific tasks.
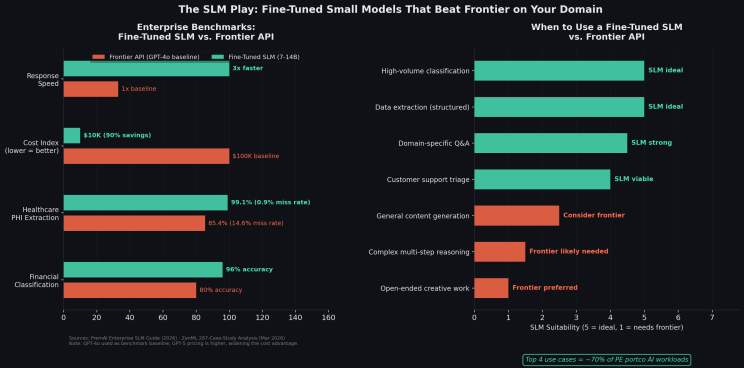
The pattern is consistent across industries. For high-volume, well-defined tasks — classification, extraction, domain-specific Q&A, and triage — a fine-tuned SLM is the better tool. It's faster, cheaper, more accurate on your data, and it keeps your proprietary information on-premise.
The caveat is real: fine-tuning isn't free. You need clean labeled data, someone who understands the process, and ongoing maintenance as your domain evolves. But the cost is measured in thousands, not hundreds of thousands. The payback period on high-volume tasks is weeks, not years.
The Mac Studio Math: What $5,999 Gets You
Let's make the economics concrete. A Mac Studio with an M3 Ultra chip and 256GB of unified memory costs $5,999 at Apple.com. That single machine can run a Qwen 3.5 or Llama 70B model at production-quality speed (e.g., roughly 25–30 tokens per second) at under 100 watts of power draw, with zero API costs and zero data leaving the building.
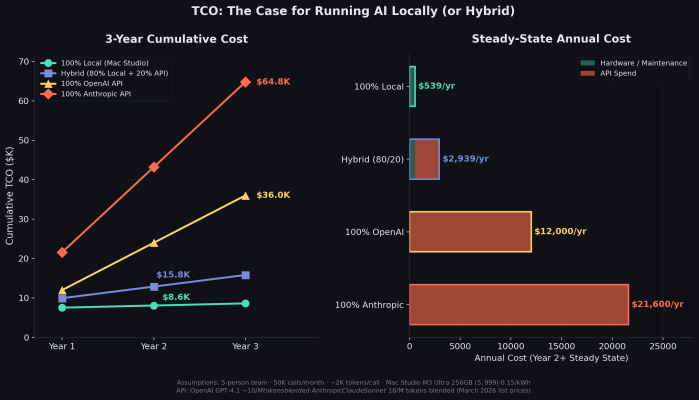
For a five-person team making roughly 50,000 AI calls per month at moderate complexity, the three-year total cost of ownership comparison is stark:
Running everything locally on a Mac Studio: $8,616 over three years. That's the all-in price for hardware, setup, maintenance, and power.
Running 100% through OpenAI's API (GPT-4.1 class, ~$10 per million tokens blended): $36,000 over three years.
Running 100% through Anthropic's API (Claude Sonnet class, ~$18 per million tokens blended): $64,800 over three years.
The most defensible approach for most organizations is a hybrid: run 80% of calls locally on open-source models (the structured, well-defined tasks) and route only the 20% that genuinely benefits from frontier quality to an API. That hybrid approach costs roughly $15,800 over three years — saving $20,200 versus all-OpenAI and $49,000 versus all-Anthropic.
And those numbers assume modest usage. For teams processing higher volumes (think customer support organizations handling thousands of tickets daily, or back-office operations classifying thousands of documents per week) the API cost scales linearly while the hardware cost stays fixed. The savings multiply.
What Percentage of PE Value Creation Is Already Covered?
I synthesized the PE-specific AI use-case frameworks published by BDO, Deloitte, FTI, and CLA in 2025–2026 and mapped them against the benchmark parity analysis above. The conclusion: roughly 80% of the AI value creation opportunities identified for PE portfolio companies are addressable with open-source models running locally.
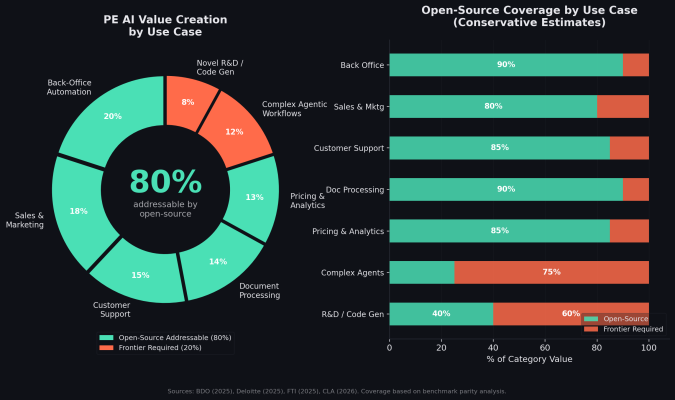
The back-office automation (document processing, invoice matching, compliance checks), sales and marketing support, customer support triage, and pricing and analytics categories collectively represent 80% of the identified value pool. They are structured, well-defined, and measurable. Open-source models match or exceed frontier performance on every relevant benchmark for these tasks.
The remaining 20% (e.g., complex agentic workflows and novel R&D) is where frontier models justify their cost. These are tasks with ambiguous inputs, multi-step reasoning chains, and no well-defined "correct answer." They matter. But they're not where most portfolio companies should start.
The implication for operating partners and portco executives is straightforward: you can begin capturing the majority of AI-driven value creation today, without signing an enterprise API contract, without sending proprietary data to a third party, and without waiting for the "right" model to come along. The right model already exists. It's sitting on HuggingFace, waiting to be downloaded.
The Valuation Question: What Would You Have to Believe?
This brings us to the uncomfortable question for investors in frontier AI companies.
OpenAI closed a $110 billion funding round in February 2026 at an $840 billion valuation. On their current annualized revenue run rate of $25 billion, that's a 34x price-to-sales multiple. On 2025 trailing revenue of $20 billion, it's 42x.
Anthropic raised at a $380 billion valuation the same month, on roughly $19 billion in annualized revenue (a 20x multiple on current run rate, or 42x on 2025 trailing revenue).
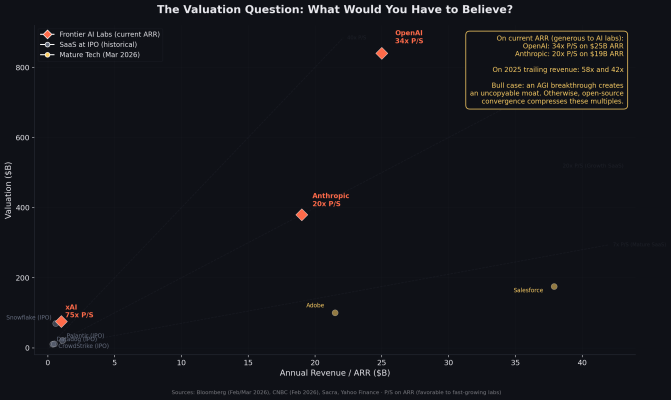
For context, Snowflake (one of the most hyped SaaS IPOs in history) went public at approximately 119x trailing revenue. Most high-growth SaaS companies go public at 15–30x. Mature tech companies like Salesforce and Adobe trade at 4–6x.
For frontier AI lab valuations to hold post-IPO, you have to believe several things simultaneously: that the performance gap stays wide enough that enterprises must pay for frontier access, that open-source alternatives stop improving at the current rate, that API pricing doesn't continue its 40–70% annual decline, and that enterprises won't shift to hybrid or local-first architectures as the tools mature.
There is one scenario that could justify these multiples: a genuine AGI breakthrough. If one of these labs achieves a step-function leap in capability — meaning true autonomous reasoning, reliable multi-day agents, scientific discovery at scale — then the winner would possess a moat that open-source cannot replicate quickly, and the revenue opportunity would dwarf current projections. This is a real possibility, and it's the strongest bull case for frontier lab valuations. But it's a bet on a specific technical breakthrough with uncertain timing, not a bet on the current business model. The current business model (selling API tokens for tasks that open-source models increasingly handle at parity) faces structural headwinds from the data above.
On every dimension except the AGI moonshot, the evidence suggests the opposite of what these valuations require. The gap is compressing. Open-source improvement is structural and multi-player. API prices are falling. And the hybrid economics are already compelling.
I'm not arguing these are bad companies or that frontier research doesn't matter. It does. The question is whether the enterprise subscription revenue that justifies these valuations is durable when the free alternative covers 80% of the use case at equivalent quality.
The Real Cost Isn't the API Bill
Here's the contrarian conclusion, and I'll state it plainly: the most value-destructive decision a portfolio company executive can make right now is to delay AI adoption because of perceived cost.
The models that already exist — available for essentially free, runnable on hardware that fits on a desk, matching or beating frontier on four of six standard benchmarks — can automate the workflows that move EBITDA. Back-office processes, customer operations, sales enablement, document processing, pricing optimization. These aren't science projects. They're execution problems with known solutions.
The real cost isn't the API bill. It's the lost months. Every quarter a portco spends debating vendor contracts and conducting "AI readiness assessments" is a quarter its competitors are using to automate, accelerate, and compound.
Start with the 80%. Run it locally. Route the hard stuff to a frontier API if and when you need it. The technology is here. The economics are clear. The only remaining variable is execution speed.
Ricky Bureau is the co-founder of GXB.VC, an AI strategy and development firm serving PE companies and their portfolio companies. He previously spent five years at McKinsey & Company.
Sources
- LMSYS Chatbot Arena Rankings (February 2026)
- SWE-bench Verified Leaderboard (March 24, 2026)
- Artificial Analysis MMLU-Pro Benchmarks (March 2026)
- VERTU Open Source LLM Leaderboard (February 2026)
- BenchLM.ai HumanEval Leaderboard (March 2026)
- Bloomberg: OpenAI $110B Funding Round (February 27, 2026)
- CNBC: Anthropic $380B Valuation (February 12, 2026)
- Sacra: OpenAI Revenue Tracker
- BDO: AI Use Case Portfolio for Private Equity (2025)
- Deloitte: Five AI-Focused Levers for PE Value Creation (2025)
- FTI: Three Plays for Driving Value Creation (2025)
- CLA: AI and PE in 2026: 6 Predictions (2026)
- PremAI: SLM vs LLM Enterprise Decision Guide (2026)
- ZenML: 287 Enterprise SLM Case Studies (March 2026)
- Apple.com: Mac Studio M3 Ultra Specifications